Sometimes, it’s interesting to learn what is being Tweeted (micro-blogged) about particular topics in real time along with who is posting which messages. NodeXL enables the extraction of individuals engaged in a particular hashtag-labeled microblogging conversation through Twitter’s application programming interface (API). This entry will provide an overview of how this is done.
Hashtags
A hashtag is a snippet of text prefaced with a # (hashtag or pound) sign which indicates that the message is focused on a particular theme or topic. In Twitter, the microblogging site, various Tweeted threads are collected around hashtags for coherent 140-character conversations from people from around the world.
A hashtag search of Twitter, then, involves the extraction of entities (Twitter accounts representing people, robots, and cyborgs) who have conversed around a particular topic. The application programming interface (API) used in NodeXL only extracts hashtag searches Tweeted in the prior week and a half.
The Hashtag Network Capture
First, start up the NodeXL template on Excel. (Either double click the icon on the desktop, or go to Start > NodeXL Excel Template.) In the NodeXL template in the horizontal menu bar, go to “Import.” Highlight “From Twitter Search Network”.
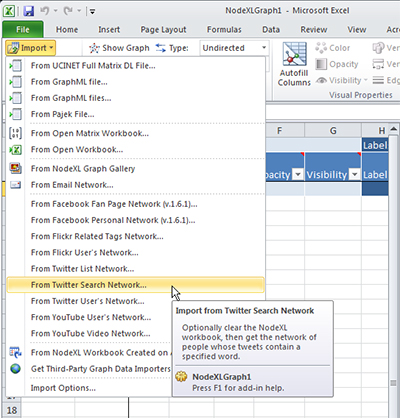
Setting the Parameters for the Data Extraction (Crawl)
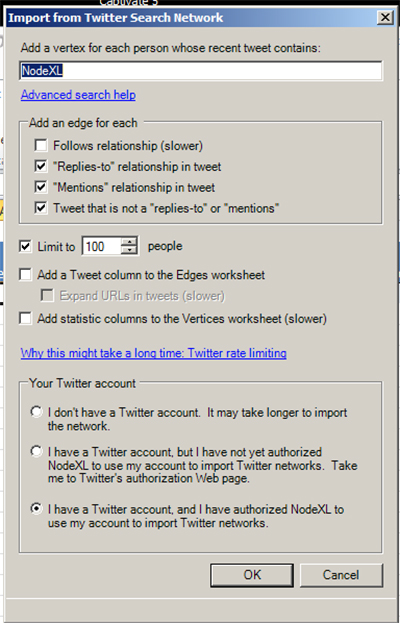
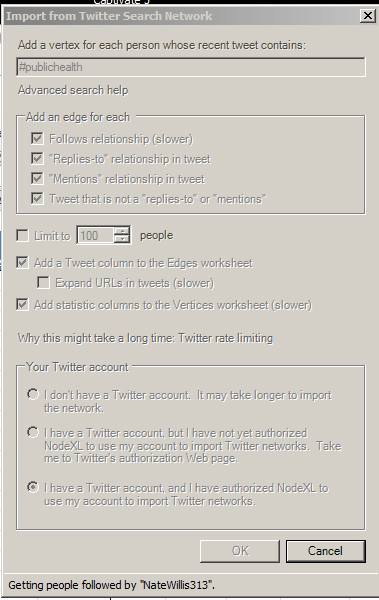
A new “Import from Twitter Search Network” will open. In the text box at the top, write in the hashtag and the search term.
For example, this crawl will be on the topic of #publichealth (https://twitter.com/search?q=%23publichealth). A screenshot of the landing page for the #publichealth Twitter feed follows.
Defining Edge Parameters
Back to setting the parameters: the edge (links or connections) settings help define how NodeXL counts connections between the vertices (nodes), which are the various Twitter accounts. “Follows relationship” refers to whether the accounts subscribe to each other’s feeds (followership). Reciprocated accounts are considered to have stronger ties than only one-directional followership.
The “’Replies-to’ relationship in tweet” refers to follows microbloggers’ behaviors in responses to others’ postings. The “’Mentions’ relationship in tweet” refers to the uses of hashtags or other terms that refer to a prior posting. The “Tweet that is not a ‘replies-to’ or ‘mentions’” refers to originating messages from a particular account that refers to a particular topic.
Setting Limits
The next section down deals with whether the individual conducting the crawl wants to limit the vertices (people). The default is set to 100 persons. However, in a hashtag search, unless a topic is trending and highly popular, no limit is necessary. In all likelihood, more than 100 individuals will not have Tweeted about that topic in the past week and a half.
If you want a text column with the latest Tweet from the accounts, check the next box which reads: “Add a Tweet column to the Edges worksheet.” To expand the URLs in Tweets (which are usually bitly links), check the box below that.
If you want a statistics column to the vertices (nodes), check that box.
Every added feature will necessarily slow the crawl.
Your Twitter Account
The final step to setting the parameters of your crawl is to define your standing with Twitter. If you do not have a Twitter account, it’s possible that your data importation will take longer. If you have a Twitter account, you may click the second radio button and set up authentication into the Twitter API for a faster crawl. In this example, the third button is clicked because this crawl is enabled through an official Twitter account.
The filled out form follows.
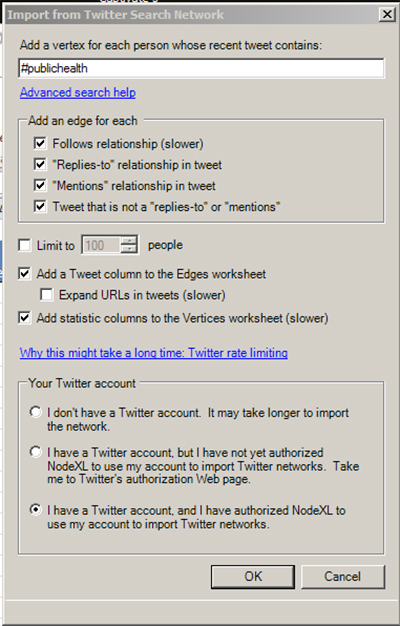
Just click “OK.” The progress is noted at the bottom of this pop-up window.
A common sight is the pause: “Reached Twitter rate limits. Pausing until…” Generally, such pauses stop the crawl for the next hour, and then the data extraction resumes.
The Completed Crawl
When the crawl is completed, a window pops up. It either says that a partial crawl was attained, or it says that text wrapping will be turned off to speed up the text import into the work book. In this context, the Text Wrapping window opened.
Click “Yes.” The text data will be placed in the Excel workbook. The populated table looks like the following.

It is a good idea to save the workbook at this time to protect against loss of the information. On helpful naming protocol is to input some parameter information in the name. In this case, this file is called #publichealthhastagsearchonTwitterunlimited. There are plenty of other possibilities for naming protocols.
Post-Download Data Processing
The next step involves processing the data now that it has been downloaded. In the NodeXL tab, go to the Graph Metrics link.
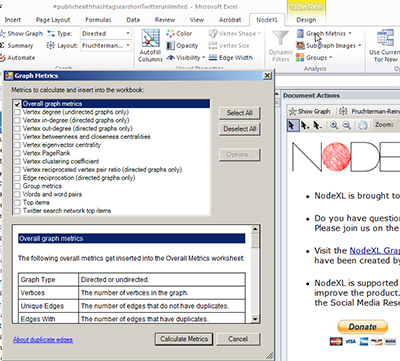
Generally, the “Select All” is an effective way to capture all relevant information. Then, click the “Calculate Metrics” button at the bottom right. Depending on the complexity of the data set and the capacity of the computer, this step may require between seconds and quite a few minutes to process. The process is completed with the presentation of the Graph Metric table.
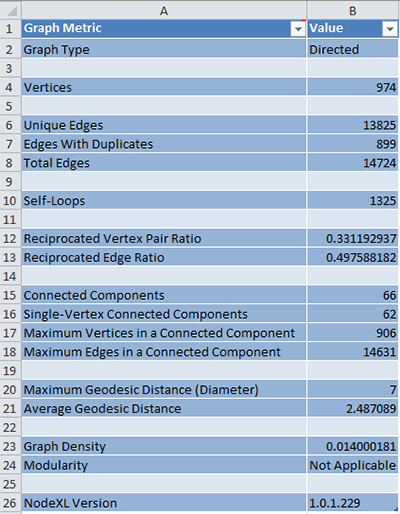
The vertices for this crawl show 974 accounts that have engaged in a microblogging conversation including #publichealth as a topic area. The edges are 13,825, which suggests quite a bit of connectivity (official following and followership connections, re-tweeting, mentions, and replies-to) between these vertices or nodes. The average geodesic distance in this network is 2.5 hops or steps, which means that the members of this social network are in fairly close proximity in terms of reaching each other. The maximum geodesic distance (diameter) is 7, or 7 hops separating the two most distance nodes in this network.
The Gist of the Conversation
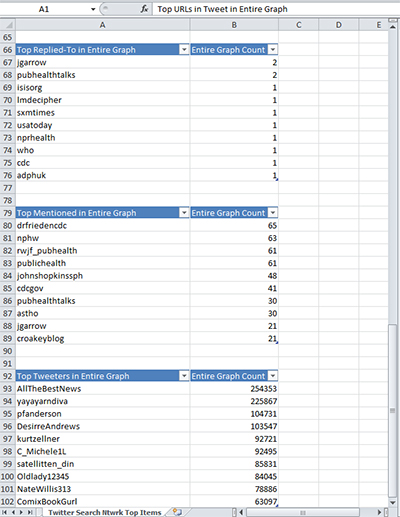
To gain a gist of the conversation, the “Twitter Search Ntwork Top Items” involves pullouts of top URLs used, top domains in the network graph, top hashtags (these may be used in combinations), top words tweeted, top word pairs, top replied to accounts, top mentions, and top Tweeters.
Finding Clusters
It is helpful to conduct one more post-processing step—the identification of groups or clusters. In the NodeXL tabbed ribbon, go to Groups > Group by Cluster. The following window should appear.
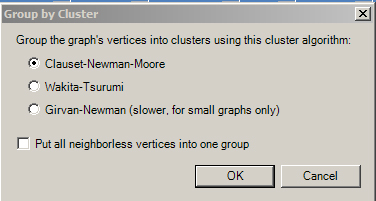
Select one method, and click “OK.” If your data set is fair large in term of the numbers of vertices (in the thousands), avoid the Girvan-Newman cluster algorithm as that is designed for small graphs only. When the clustering is completed, the groups sheet will be displayed. You may drag the vertical scroll bar down to see how many clusters were extracted. In this case, 79 were extracted (read the G79, not the number in the Excel table).
In many hashtag searches, there are a wide range of types of clusters or groups of accounts that may be identified. For a topic like “public health,” there are many stakeholders. In a typical hashtag crawl, there will likely be diverse clusters or statistically-identified constituencies.
The Visualization
Now, it is time to create the visualization. This is done in the graph pane to the right. Under “Document Actions,” you will find the button which you may use to choose the type of graph visualization algorithm (from the dropdown menu) you want to apply to the data.

Given the size of this data set (relatively small), this would be a strong candidate for the Harel-Koren Fast Multiscale layout algorithm. After that is selected, go to “Show Graph”.

Be sure to save this Excel workbook. With the NodeXL template, you may use this again to do another data extraction at a later date using the same parameters.
The Longer Trajectory of a Microblogged Conversation
To get to the actual contents of recent Tweets, it is also possible to go to a search engine like Google and put in the “#korea and Twitter”. This brings us to the site (https://twitter.com/search?q=%23korea), which collates all the messages and Twitpics tagged with #korea, going back months.
Advanced Search Features on Twitter
Twitter enables advanced search features (based on Boolean methods). For more information on this, go to their Help Center.
Final Note: NodeXL is a free and open-source tool that is available from Microsoft’s CodePlex site (which is a space for project hosting for open-source software), and it is sponsored by the Social Media Research Foundation.