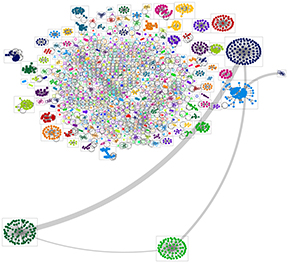
A content network consists of an analysis of related clusters of information. Social media platforms that enable the sharing of contents align with research into crowd-sourcing and self-organizing behaviors, where individuals working often in isolation or in small groups share contents that benefit people on the whole. One of the most popular digital content sharing sites is Google’s YouTube, where people may share videos of themselves.
An extraction of a video network is based on the metadata used to label the video contents, and this extraction will result in a related tags crawl.
Cat Videos
A popular meme involves videos of cats and their antics. A search of cat videos on YouTube surface two talking cats, skydiving cats (filmed in front of a green screen), grumpy cats, cats v. dogs, and other themes. This huge amount of human attention to cats has led to the phenomena of “catvertising” (using cats in word-of-mouth advertising). In celebration of this theme, this blog entry will focus on a crawl of “cat” on YouTube. (Also, “cat” is pretty disambiguated.)
Continue reading “The NodeXL Series: Conducting a Data Extraction of a YouTube Video Network (Part 7)” →
 “Tapping Social Media Data with NCapture and NVivo” will be offered 1:30-3:30 p.m. Friday, April 2, on Zoom. This presentation provides an overview of the NCapture browser add-on (to Google Chrome and Microsoft IE) as a tool for extracting information from social media platforms and will explore how the extracted data is analyzed using NVivo 12 Plus / NVivo, a qualitative and mixed methods data analysis tool. (The NVivo for Mac now enables this functionality as well.)
“Tapping Social Media Data with NCapture and NVivo” will be offered 1:30-3:30 p.m. Friday, April 2, on Zoom. This presentation provides an overview of the NCapture browser add-on (to Google Chrome and Microsoft IE) as a tool for extracting information from social media platforms and will explore how the extracted data is analyzed using NVivo 12 Plus / NVivo, a qualitative and mixed methods data analysis tool. (The NVivo for Mac now enables this functionality as well.)