Per the prior entry, if a hashtag search is very time-dependent and ephemeral / transitory, the user accounts and relationships created around entities (people, organizations, companies, robots, and “cyborgs”) tend to be more stable. While the research does not necessarily show that a follower / following sort of reciprocal relationship means that all Tweets are read and engaged, these do show a sense of some initial commitment and public declaration of a kind of relationship. (Those interested I the research may find that there are surprises, such as that popularity and positive word-of-mouth does not necessarily translate to sales commitments. Further, there is sufficient system gaming by using ‘bot and other accounts that a more accurate read of a user network requires some more digging and critical thinking analysis.)
First, it helps to pick a “target.” A search on a search engine of an organization’s name “and Twitter” will often lead to the account information. For our purposes, we’ll go with the Centers for Disease Control and Prevention (CDC), in part because they have a clear social media strategy to engage their constituents.
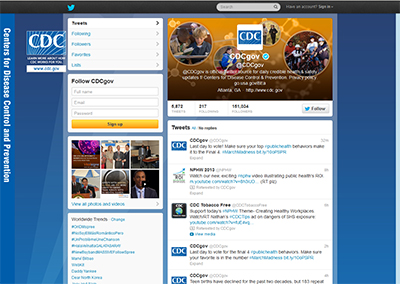
A Limited Crawl of the CDCGov User Network on Twitter
The official Twitter account for the CDCGov site is https://twitter.com/CDCgov. (Do read the fine print carefully to make sure that you haven’t landed on a farce site. There are many pretenders, some not-so-subtle, and others very elusively so.)
Continue reading “The NodeXL Series: Conducting a Twitter User Network Crawl (Part 6)” →